Introduction
In this post, we compare the client-server architecture to peer-to-peer (P2P) networks and determine when the client-server architecture is better than P2P. For those of you unwilling to spend a few minutes reading through the article, I’ll let you in on a spoiler – peer-to-peer is always better than client-server.
To understand why, let’s first examine some definitions and history between the two models.
Client-Server Introduction
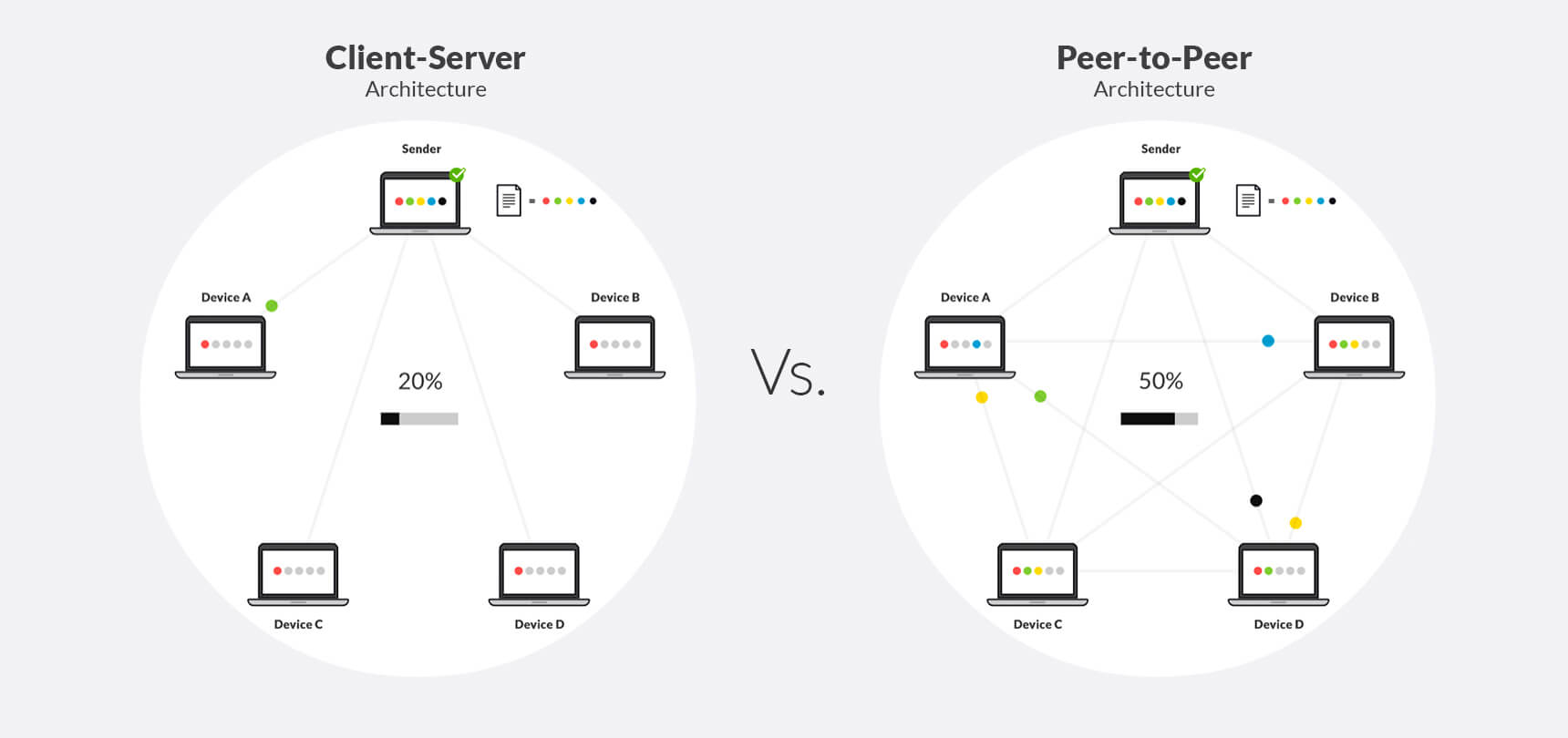
With the widespread adoption of the World Wide Web and HTTP in the mid-1990s, the Internet was transformed from an early peer-to-peer network into a content consumption network. With this transformation, the client-server architecture became the most commonly used approach for data transfer with new terms like “webserver” cementing the idea of dedicated computer systems and a server model for this content. The client-server architecture designates one computer or host as a server and other PCs as clients. In this server model, the server needs to be online all the time with good connectivity. The server provides its clients with data, and can also receive data from clients. Some examples of widely used client-server applications are HTTP, FTP, rsync and Cloud Services. All of these applications have specific server-side functionality that implements the protocol but the roles of supplier and consumer of resources are clearly divided.
Peer to Peer (P2P) Introduction
The peer-to-peer model differs in that all hosts are equally privileged and act as both suppliers and consumers of resources, such as network bandwidth and computer processing. Each computer is considered a node in the system and together these nodes form the P2P network. The early Internet was designed as a peer to peer network where all computer systems were equally privileged and most interactions were bi-directional. When the Internet became a content network with the advent of the web browser, the shift towards client-server was immediate as the primary use case on the internet became content consumption.
But with the advent of early file sharing networks based on peer-to-peer architectures such as napster (1999), gnutella, kazaa and later, bittorrent, interest in P2P file sharing and peer-to-peer architectures dramatically increased and were seen as unique in overcoming obvious limitations in client-server systems. Today these peer-to-peer concepts continue to evolve inside the enterprise with P2P software like Resilio Sync (formerly bittorrent sync) and across new technology sectors such as blockchain, bitcoin and other cryptocurrency.
With our definitions out of the way, let’s examine some challenges with Client-server networks.
Availability
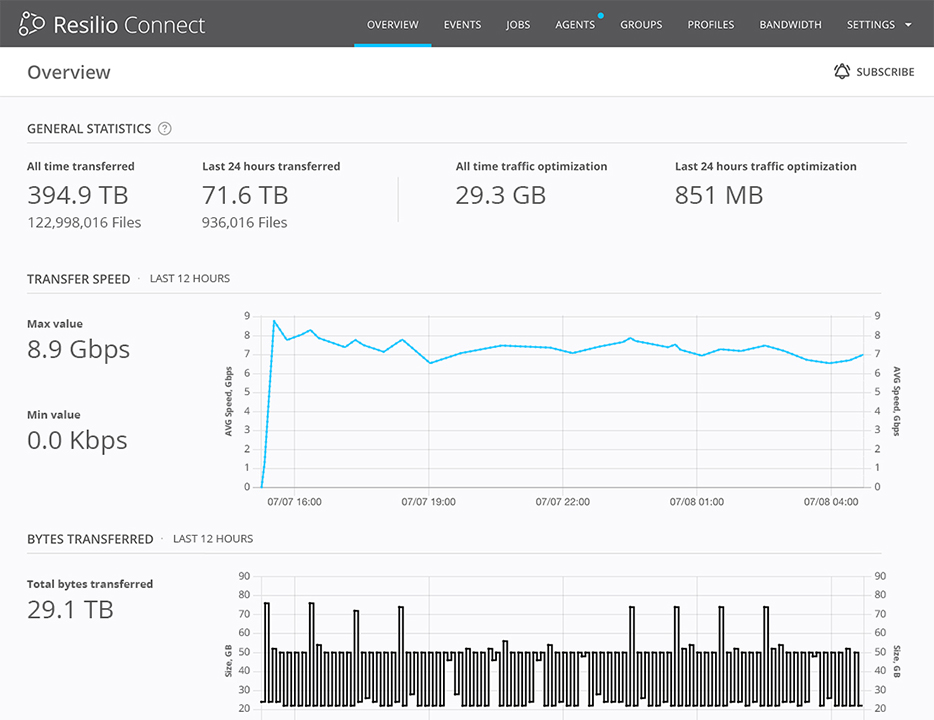
The most obvious problem faced by all client-server applications is one of availability. With a dedicated server model, the server MUST be online and available to the clients at all times, or the application simply will not work. Many things can impact server availability from software problems, operating system errors and hardware failures. Routing errors and network disruption can also impact availability. In fact, with so many things that can go wrong (any one of which takes down your server – which takes down your application), it is little wonder that considerable time and resources are spent making servers highly available and trying to anticipate problems in advance. Specific departments such as Operations are often completely dedicated to the availability challenge and entire industries, such as Content Delivery Networks (CDNs) and Cloud Computing have been born to overcome the availability limitations of the client-server model, usually by allocating even more resources to the server-side of the model to ensure availability. All of this adds complexity and cost as high availability demands that the system switches to a backup hardware or internet service provider if it’s disrupted for any reason for the application to continue to operate smoothly. This problem is quite complex since you need to keep data synchronized between your live server and backup server, maintain alternate service providers and properly plan software and hardware updates in advance to support uninterrupted service operation.
In a peer-to-peer network, each client is also the server. If the central machine is not available the service can be provided by any available client or a group of clients each operating as nodes on the network. The peer-to-peer system will find the best clients and will request service from them. This gives you service availability that doesn’t depend on one machine and doesn’t require the development of any complex high availability solution.
If application availability is a challenge that keeps you up at night, you might be interested in learning more about an inherently highly available peer-to-peer solution for syncing and transferring enterprise data in real-time, by visiting the Resilio Connect product page.
In summary, peer to peer systems are naturally fault-tolerant and more available than client-server systems. Client-server systems can be made highly available only with great cost and additional complexity.
High Load
Another recurring problem with client-server applications is high load or unexpected demand on the server. This is really a subset of the availability problem above, but one that is difficult to anticipate and expensive to solve. For the application to function properly in the client-server model, you must have sufficient capacity at the server to satisfy the demand of the client at any time. The more popular the application becomes, the more clients that show up requesting access to the server. Planning for the worst (unexpected demand) is a major challenge of the client-server architecture. A single powerful client that consumes data faster than the others could consume all the networking, disk operation and server CPU. You want all clients to have access to the server. Therefore you need to limit clients to certain consumption levels, so each of them can get minimal server resources. This approach makes certain the powerful client won’t disrupt the other clients. But in reality, it usually means that the file server always serves a client in a limited way, even if it’s not overloaded and can operate faster which is an inefficient allocation of resources.
In the enterprise setting, solving high load usually means allocating more resources to servers, storage and infrastructure, like the network. But when the application is not in peak demand (95%+ of the time) these additional resources are not needed and are, in fact, wasted. Planning for increased load often means large capital expense projects to buy more storage, more network and more servers and may do little more than push the bottleneck to some other component of the system.
By comparison, peer to peer architectures convert each node to a server that can provide additional service. It has the property where every new user comes with additional capacity, helping to solve high load problems organically. The problem of the powerful client consuming all of the resources in the client-server model is actually an asset in the peer-to-peer model, where this peer acts as a super node and is able to serve other peers at greater levels than the average node.
To put the differences between these two models in perspective, in 2008, the bittorrent network was moving over 1 EB (exabyte) of data every month. At the same time, the most popular streaming site on the internet (no need to mention the name) was on a run rate to move 1 EB of data every 2.4 years. One system uses the client-server architecture, the other uses a peer to peer architecture.
And Netflix was still mailing DVDs.
In summary, peer-to-peer systems never suffer from high load challenges, and actually get stronger and more capable with increased demand.
Scalability
Scalability means growing with your application, and it’s a real challenge with the client server model. Everyone knows, enterprise data is not getting smaller and the number of files is always increasing. If your company is growing, you are adding more users and more employees as well and all of this places increased demand on your servers. Scaling the server infrastructure in response is also capital intensive in the same way as planning for peak load.
Each server needs to be planned for the specific amount of clients it will support. When the number of clients grows, the server CPU, memory, networking, and disk performance need to grow as well, and can eventually reach a point when the server stops operation. If you have more clients than a single server can serve, you probably need to deploy several servers. This means designing a system to balance and distribute load between servers, in addition to the high availability system we discussed previously.
Scaling your infrastructure to handle larger data or more users means massive capital expense to increase server, storage and network infrastructure. And again, you may find all you’ve accomplished is moving the bottleneck to some other component in the system.
In a peer to peer model, the more devices you have in a network, the more devices will be able to participate in data delivery and the more infrastructure each brings to the party. They will all participate in terms of network, CPU and storage, distributing this load from a central server. In this way, peer to peer systems can be considered organically scalable. Meaning increased scale comes for free with increased demand instead of the massive capital expense projects inherent in the client server model.
In summary, P2P systems are organically scalable. More demand means more supply making them ideal for applications that involve large data and/or many users/employees.
Below we cite some example applications that are common in the enterprise and describe how peer to peer architectures are ideal in solving each one.
Use Case: Build Distribution
Video games are getting larger. Today’s gaming consoles are 4K capable and will soon be 8K capable, meaning there is no scenario where the amount of data that must be moved in the production of new titles goes down. The problem is generalized to the entire software industry as platforms proliferate and build sizes increase. Development companies struggle to deliver builds faster to remote offices across the globe, to accommodate the increasing trend of remote employees working from home or to distribute builds within one office to hundreds of fast QA machines on a LAN. In a client-server model, all remote offices will download builds from a build machine. The speed limitation will be determined by the network channel that serves the build to all remote offices. A peer-to-peer network model would split the build into independent blocks that could travel between offices independently. This approach removes network limitation from the main office and combines the speed of all remote offices to deliver builds faster. Usually, you can get 3-5 times faster on a peer-to-peer architecture than on client-server.
Another issue is distributing builds within a single office from a central server. The fast QA machines completely overload the central server network and CPU, bringing the centralized server to an unusable state. Utilizing a local server or storage array in each office is difficult to manage and the QA machines can still overload this server or storage array, rate limiting the distribution of builds and wasting development time. Combined, this is an almost unsolvable scalability issue. As we discussed above, a peer-to-peer approach is better when many clients request access to the data. Each QA machine can seed the data to other machines, keeping the server in a healthy state and delivering builds blazingly fast.
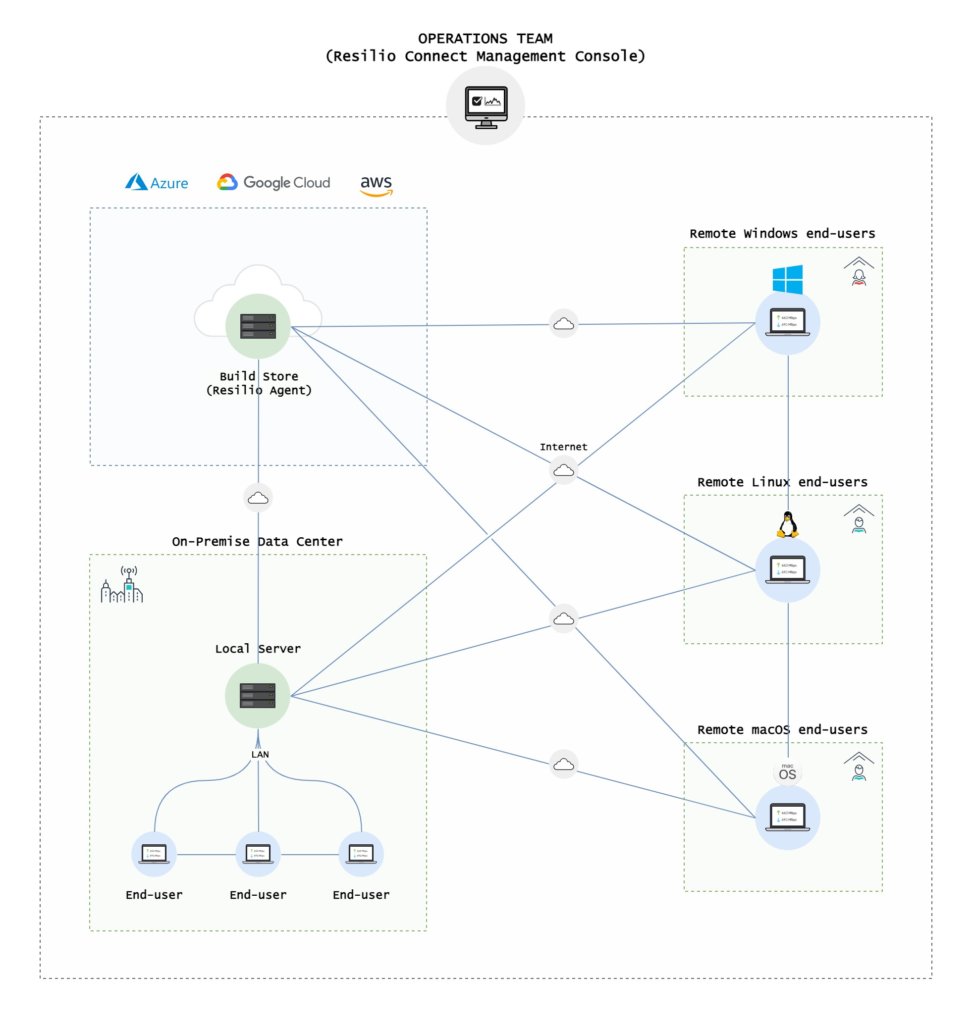
Use Case: Data Delivery to Remote Offices
Delivering data to a remote office usually involves overloading the central server. Even if the speed of each office is fast, when you have many of them it adds up and requires huge bandwidth channels to the central office. A problem can occur when you need to deliver large volumes of data such as documents, video or images. The peer-to-peer approach solves that by allowing each remote office to participate in data delivery. This reduces the load on the centralized server, and significantly reduces central server and networking requirements.
Furthermore, remote offices often have limited bandwidth to each office. Moving the same data over and over again utilizing this weak link is wasteful and inefficient. This is exactly what happens in a client-server model.
P2P software solves this naturally by finding the best source for the data, the best routing between data sources regardless if it is a local dedicated server or remote server. Once the block of the data is present in the remote office, it won’t necessarily be downloaded from the central data center again, saving precious bandwidth over the branch office link.
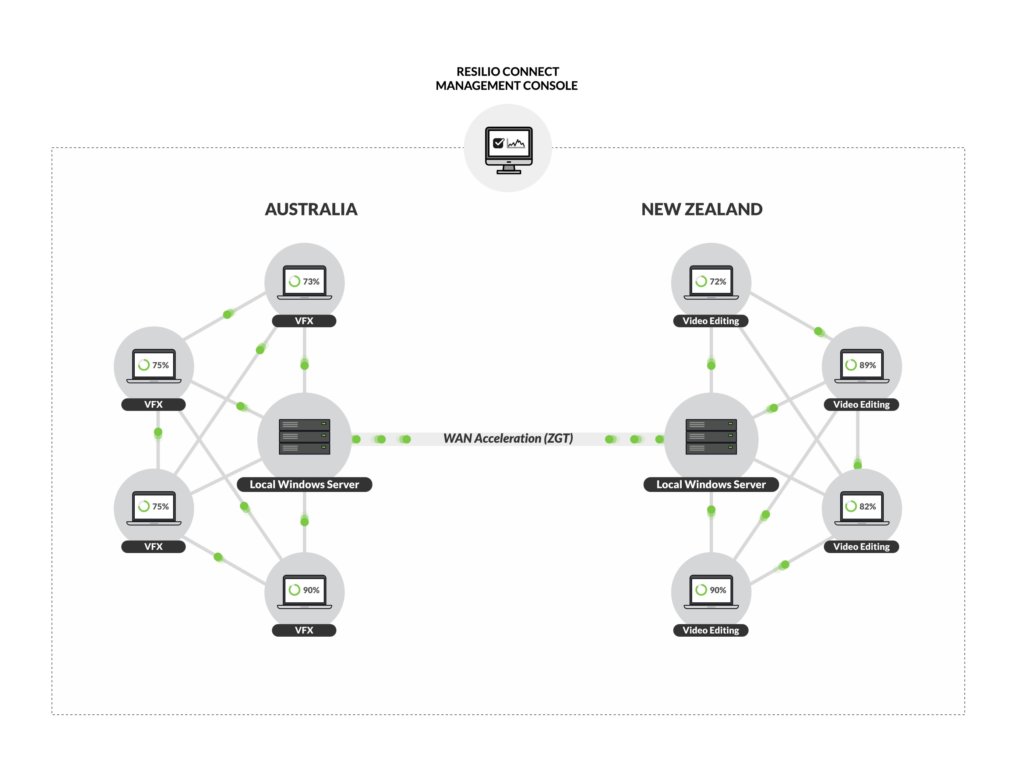
Use Case: Endpoint Management Systems
Patching and updating a large number of endpoint operating systems is a challenge that is particularly suited for P2P software. The file sizes are large, for example, an update from Microsoft can be many GB in size, the pcs or hosts to be updated often number in the 1,000’s and the infrastructure to many branch offices or remote workers is often limited and unreliable. Centrally serving updates in a client server model, makes no sense considering the limitation of the branch office internet mentioned in the section above. Additionally, the update application is sporadic in nature, but peak demand for a critical update (such as a security vulnerability) can be intense. Exposure to a vulnerability for even a day can be catastrophic. Solutions like branch cache from Microsoft are examples of solving the availability challenge with more servers and more infrastructure.
Peer to peer distribution of these updates is far more efficient and much faster than traditional client server models. The updates can be delivered at peak speed without a massive investment in server infrastructure that has to be managed for each branch office. The solution is ideal for large enterprises like financial institutions, nonprofit and retail settings where many office locations must be managed and secured.
Busting common P2P myths
Myth #1:
P2P networks are only faster when you download from many peers
While the speed of the P2P network grows as more clients join the transfer. The point to point and distribution of data from one node to several nodes is faster too.
Myth #2:
P2P networks expose your network and computers to viruses, hackers, and other security risks
This misconception originates in the popular private P2P use case of illegal file sharing. Illegal file sharing and intellectual property theft expose your infrastructure and computers to all the problems. The risk for an enterprise P2P application does not exist, since all entities participating in distribution are secure enterprise machines.
Myth #3:
P2P networks are less secure than client-server networks
As we saw above, peer to peer is just a way to establish a connection and assign roles between machines. It does need additional security mechanisms that can perform mutual authentication and authorization, as well as access control and traffic encryption. However, these additional security features are built into enterprise P2P solutions like Resilio Connect.
How much faster are P2P networks vs. client-server networks?
We explored this question in a detailed whitepaper: Why P2P is faster. In a nutshell, P2P is always faster. How much faster depends on data size and scale. The larger they are, the bigger the differences. In the example in the article, client-server took 3X as long to send a 100GB file.
It’s important to remember that using P2P is not only faster, but also:
- Provides significant savings on equipment and infrastructure
- A more robust and resilient topology